



One of the perks of working for XebiaLabs is our training allowance: as a software engineer you get a generous budget and 5 training days for your personal development. You’re free to spend it on whatever will benefit you: internal or external trainings, conferences, as well as massive open online courses.
I’ve chosen to use my 2017 bound budget on an Apache Spark Data Science training hosted by GoDataDriven. In retrospective, aside from the fact that I’ve found the trainers knowledgeable and the material well-rounded, hereby the top reasons why I think software engineers can benefit too from immersing themselves into data science and Spark™ technology.
1. Artificial intelligence is everywhere, get to know the open source code behind it.
“AI has always been one of the most exciting applications of big data and Apache Spark.” - Matei Zaharia, the creator of Apache Spark™
Whether I am thinking of smart planning algorithms to brake world records of the famous travelling salesman problem (TSP), predictive distribution models, better diagnostic algorithms in healthcare, it is difficult to escape the reality of how much data science is picking up ground across all industries.


Spark’s Machine Learning Library was covered on the second day of training. For me this was also the day with the steepest learning curve and loads of machine learning concepts: (stochastic) gradient descent, random decision forests in classification, Gaussian mixtures (GMMs), n-Gram-based classification, statistical fit, overfitting and underfitting data in machine learning algorithms, linear regression, alternating least squares method for collaborative filtering, matrix factorisation in recommender systems.
After this training, I still consider myself very far away from being a proficient data scientist. Nonetheless, I am informed on what’s out there to be leveraged as open source tools and I’ve heard of the concepts and algorithms to be further mastered when implementing particular AI use-cases.
2. So what? Data scientist and software engineer are two different disciplines
I agree that specialising in a particular discipline and set of technologies (X-functional) is better than being a jack of all trades, thus above statement is justified. However reality is never that black or white in a such dynamic field as technology.
 The only constant is change, continuous improvement. And improvement may require also a certain degree of experimentation by seizing opportunities to learn new skills.
The only constant is change, continuous improvement. And improvement may require also a certain degree of experimentation by seizing opportunities to learn new skills.
3. Apache Spark is a must for big data hackers.
Like so many controversial topics, the difference between “Big” data and lower-case data might be best explained with a joke:
“If it fits in RAM, it’s not Big Data.” - Unknown (If you know, pass it along!)
Working at the XL Deploy product on automating and standardising complex application deployments for enterprise scale clients, means often dealing with new infrastructure, depending on each client’s database engine and application server requirements engineering.
 The
The App Definition & Development Overview at Cloud Native Landscape Project
Cloud Native Landscape Projectextract above, Spark and Hadoop
appear alongside SQL and NoSQL databases & data analytics tools. They are just for that day when your backlog task is to create SQL queries for a reporting dashboard mining data of the magnitude of
petabytes

4. Apache Spark™ is an Engine for Large-Scale Data Processing
No doubt that Python is the perfect language for prototyping data science/machine learning fields. However there is more to Apache Spark™ than only its Machine Learning Library.
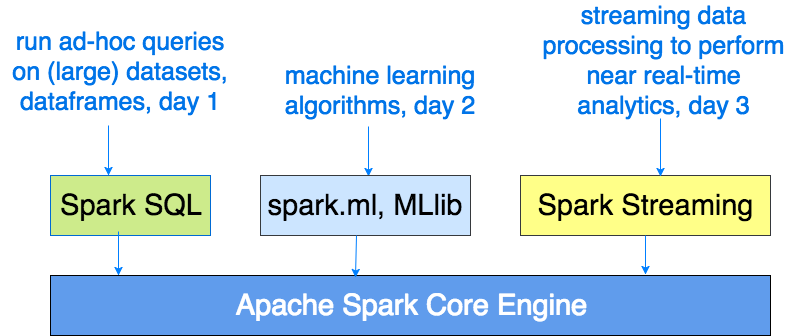
What I liked about days 1&3 of the training is that both trainers have drawn clear overviews on the motivation to leverage Apache Spark™ on the engineering side of things:
- Lightning speed of computation because data are loaded in distributed memory (RAM) over a cluster of machines, making Spark suitable for faster data-sharing needs across parallel jobs.
- Comparison to
Hadoop Map-Reduce jobshaving intermediate computation results I/O bound, thus making Hadoop mostly suitable for use cases where processing times are not much of a concern: such as ETLs (Extract/Transform/Load), data consolidation, and cleansing. - Unified approach to solve
Batch,Streaming, andInteractiveuse cases - Highly accessible through standard APIs built in
Java,Scala,Python,SQL(for interactive queries)
5. If you take notes, you might get hooked on notebooks
As a software engineer, I strive to use the right tool for the job. In my current project there is quite a polyglot landscape of general purpose programming languages: Java, Scala, Python, some Groovy DSL. Whenever I needed to interact with the Python SDK for XL-Deploy code, I’ve been using IntelliJ IDEA and its Python Plugin. During the training, I got introduced to working with Jupyther Notebook, an open source project for web-based notebooks that enables data-driven, interactive data analytics and collaborative documents with cells of code, markdown, images etc.
The installation and usage came in two flavors:
- Spark standalone with PySpark and Jupyter notebook local installation which I describe in below section
Setup your own Apache Spark, PySpark and Jupyter Notebooks Playground - ssh tunnel with port forwarding access to a Google Cloud DataProc managed Spark service which challenged the trainer to monitor and resize the cluster when everyone started to work on the Spark Streaming API exercises on the cloud managed cluster
Are you a Docker fan? You might like Jupyter Notebook Python, Scala, R, Spark, Mesos Stack Wait! There are Apache Zeppelin notebooks too, now I need a recommender system on notebooks 😃😄😆
{kind=link}
Setup your own Apache Spark, PySpark and Jupyter Notebooks Playground
Has your interest been sparked? Are you curious to test drive Apache Spark™ APIs? Did you know that Spark has a convenient shell (REPL: Read-Eval-Print-Loop) and examples to interactively learn the APIs?
There are a multitude of online resources to get your machine equipped for a test drive. Bellow I describe my own installation on macOS.
Before installing Spark, make sure you have JDK 8+, Scala 2.11+, Python 2.7.9+/3.4+ (recommended as pip is included). Then, visit the Spark downloads page. Select the latest Spark release, a prebuilt package for Hadoop, and download it directly.
$ sudo cp ~/Downloads/spark-2.2.1-bin-hadoop2.7.tgz /opt/
$ cd /opt/
$ sudo tar -xzf spark-2.2.1-bin-hadoop2.7.tgz
$ ln -s spark-2.2.1-bin-hadoop2.7 /opt/spark`
Having the symbolic link will make the path reference shorter and you will be able to download and use multiple Spark versions. Finally, tell your bash where to find Spark. To do so, configure your $PATH variable by adding the following lines in your .bash_profile file:
export SPARK_HOME=/opt/spark
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS='notebook'
export PATH=$PATH:$SPARK_HOME/bin:$PYSPARK_DRIVER_PYTHON:$PYSPARK_DRIVER_PYTHON_OPTS
Check that you have Java, Scala, Python added to your $PATH too:
export JAVA_HOME=$(/usr/libexec/java_home -v 1.8)
export JRE_HOME=$JAVA_HOME/jre
export SCALA_HOME=/opt/scala-2.12.3
export PYTHON_HOME=/usr/local/bin/python3
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$SCALA_HOME/bin:$PYTHON_HOME
While using Spark, most data engineers recommends to develop either in Scala (which is the ‘native’ Spark language) or in Python through complete PySpark API. At this point you can check your standalone installation via Spark’s shell:
| Scala | Python |
|---|---|
| $ spark-shell | $ pyspark |
Standalone Spark installation comes also with quite some samples. For the Scala sample that computes an approximation to pi, you can just open a terminal and type: run-example SparkPi. You will also be able to access the Spark Web UI at: http://localhost:4040.
Virtual Python Environment builder for PySpark data science project with virtualenv
virtualenv is a tool to create isolated Python environments.
First setup a project path:
$ export PY_WORKON_HOME=~/pyEnvs
$ mkdir -p $PY_WORKON_HOME
$ cd $PY_WORKON_HOME
If you’re running Python 2.7.9+ (not recommended), pip the Python package manager is already installed, but you’ll have to install virtualenv and then create an isolated data science Python environment, named pySpark-env as below:
$ python -m pip install --upgrade virtualenv
$ virtualenv pySpark-env
When running Python 3.4+ (recommended), you already have built-in support for virtual environments with venv package:
$ python3 -m venv $PY_WORKON_HOME/pySpark-env
The source command actives the Python virtual environment.
$ source pySpark-env/bin/activate
To complete the full environment setup, install general purpose modules needed for data science projects with Python and Spark, and start Jupyter Notebook on the port of your choice (hereby 8988):
$ pip install pyspark findspark jupyter sklearn scipy numpy pandas matplotlib
$ jupyter notebook --port 8988
Ta da! 🎉 You’re all setup to create new or import existing Python3 notebooks:
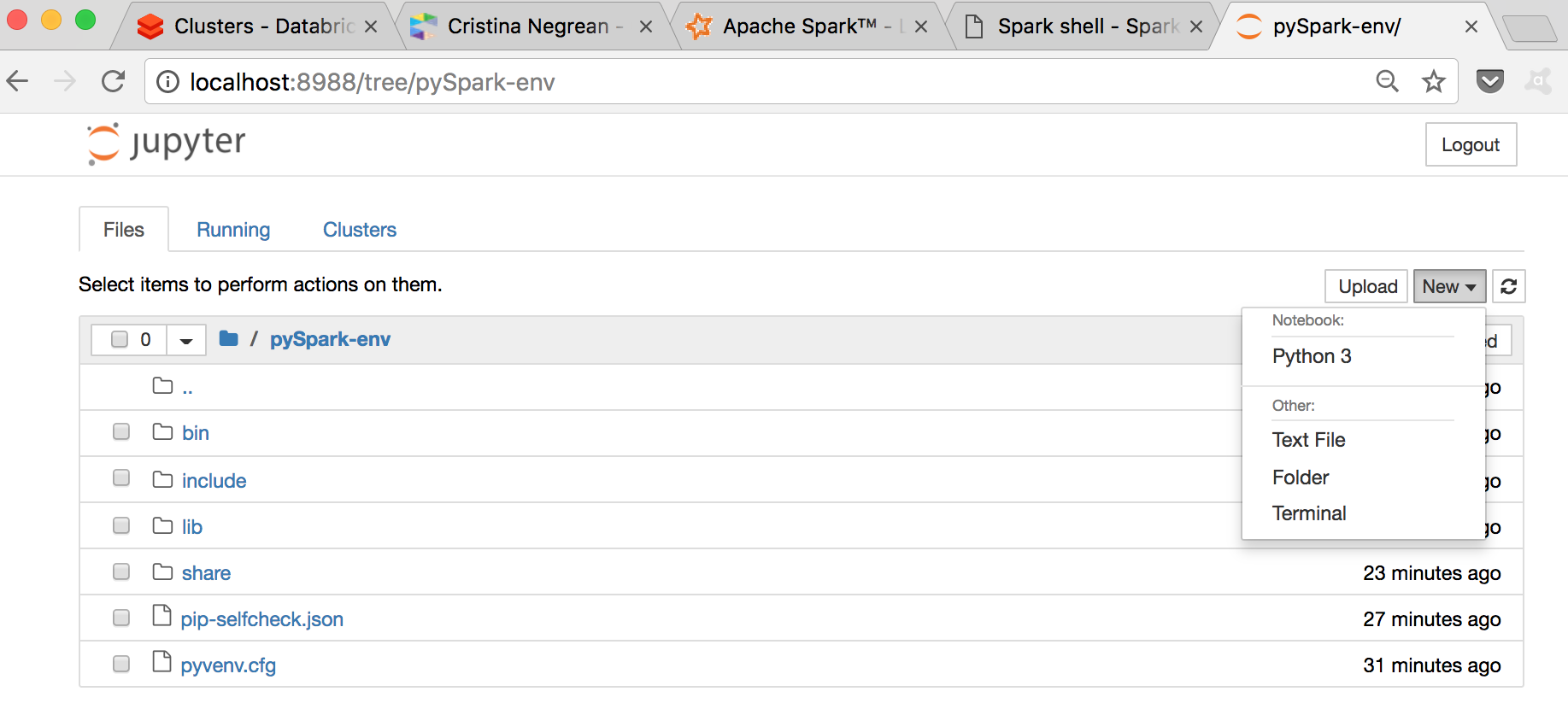
In order to tear down the virtual environment pySpark-env, just type: deactivate in your terminal, after stoping the Jupyter NotebookApp web server.
The Reference Shelf
I am not disclosing the training material, however hereby some resources that I’ve found helpful along the way: